


Real-Time Bond Yield to Maturity
Streaming with Kafka and Redis



Table of Contents
Intro
Our Solution Architecure
Kafka Streams and our Topology Configuration
What is Kafka Streams?
Our Topology
Configuring the Kafka Stream
Starting the Kafka Stream
Storing and Publishing YTM with Redis
Redis Adapter Implementation
Streaming YTM Updated via WebSockets
Retrieving and Subscribing Data from Redis
Bridging Redis and WebSocket
WebSocket Implementation
Conclusion
Futher Reading and ResourcesIntro
At Trade Republic, we’re all about helping customers make the best investment decisions, so when we decided to roll out bond trading, we wanted to build something that truly stands out. A system that makes the often-complex world of bonds as intuitive and insightful as possible.
Here’s a thing about bond trading: it’s not just about price quotes. Sure, quotes tell you what a bond is trading for right now, but that’s only part of the story. When trading bonds, the real star of the show is Yield to Maturity (YTM). If you’re new to this term, think of YTM as the ultimate measure of what a bond is actually worth over time. It’s the total return you can expect if you hold onto the bond until it matures, factoring in interest payments and the price you paid. Basically, it’s what investors care about most when deciding whether a bond is a good investment.
On our platform, we’re already great at serving up real-time quotes and historical charts for other instruments. So when we added bonds, we wanted to make it just as seamless — real-time updates, easy to track and scalable for millions of users.
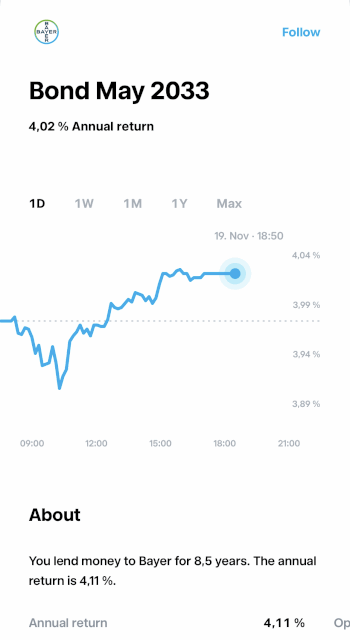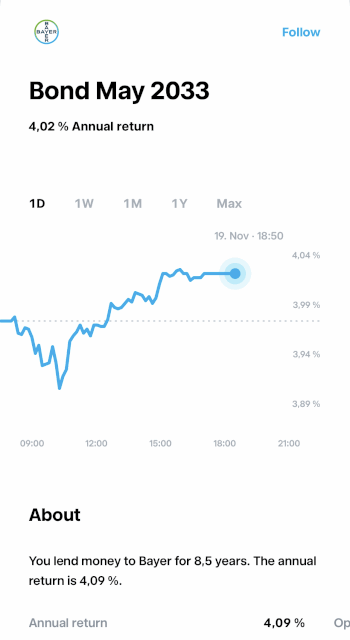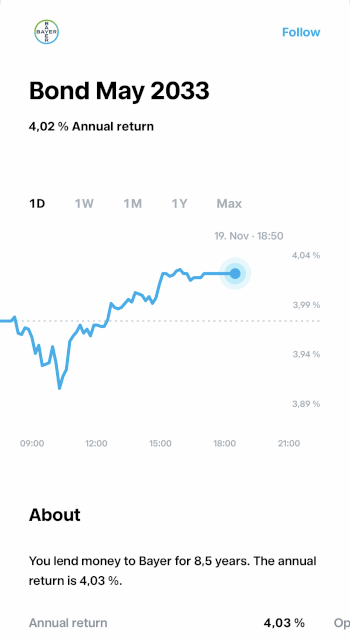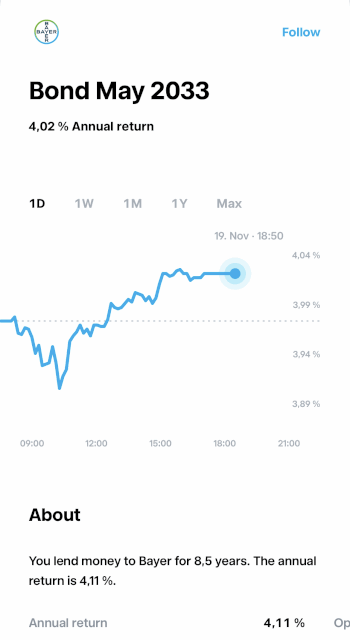
Of course, this wasn’t as simple as flipping a switch. YTM isn’t a static value — it has to be calculated in real time based on incoming market data. So, we needed to design a pipeline that could take raw quote data, transform it into YTM on the fly, and then deliver those updates to our customers without breaking a sweat (or the system).
This blog is all about how we made that happen. From using Kafka Streams to process quotes and calculate YTM, to leveraging Redis and WebSockets to stream updates in real time. If you’re into real-time systems or just curious about our engineering approach, stick around — you’re in for a fun ride.
Our Solution Architecture
In order to deliver real-time YTM updates, we designed a system that’s fast, scalable, and reliable. The architecture revolves around processing bond quotes as they come in, calculating YTM on the fly, and streaming those updates to all connected customers.

At its core, we leverage Kafka Streams to process the raw quotes flowing through our system, calculate the YTM, and distribute the results. The calculated YTM is sent to both Redis and a separate Kafka topic. Redis serves as the backbone for delivering real-time updates to our clients via WebSockets, while the Kafka topic is used for downstream processing, such as generating historical YTM charts.
For real-time updates, we use Redis cluster with Sharded Pub/Sub, a critical decision for scalability. While Redis Pub/Sub is powerful, a non-sharded Pub/Sub setup in a clustered environment can negatively impact performance and scalability, as every message would be broadcasted across all nodes in the cluster.
When a client subscribes to a bond instrument, the ytm-stream service retrieves the latest YTM value from Redis and streams it to the user. Any subsequent updates are pushed via a subscription to Redis channels. To optimise resource usage, the ytm-stream service maintains a single connection to Redis per service instance, no matter how many clients are connected.
This setup lets us handle live updates seamlessly while keeping things lightweight and scalable. Whether users are tracking a bond’s YTM in real time or looking at its historical trends, the architecture has them covered. Let’s dig into how it all works.
Kafka Streams and our Topology Configuration
What is Kafka Streams?
Kafka Streams is a powerful library for building real-time data processing applications on top of Apache Kafka. Unlike a traditional Kafka consumer, which just reads messages, Kafka Streams allows you to transform, aggregate, and enrich data directly within the stream. Essentially, it’s a toolkit for processing data in motion, making it ideal for tasks like computing metrics, filtering data, or joining streams together.
At its core, Kafka Streams operates with a topology — a directed graph of stream processing nodes. Each node represents an operation, like consuming data, transforming it, or writing the results back to Kafka. This approach makes it both scalable and declarative, so you can define how data flows through your system without worrying too much about the underlying mechanics.
Our Topology
As mentioned before, our the core of our pipeline looks something like this:
Stream quotes: The stream starts by consuming raw bond quote data from a Kafka topic.
Calculate YTM: For each incoming quote, we calculate the corresponding YTM based on financial formulas. This is where the magic happens — turning raw data into actionable metrics.
Publish results: The calculated YTM is sent to:
Redis, so we can stream updates to our customers through WebSockets.
A new Kafka topic, so other services (like historical YTM charts) can process the data further.
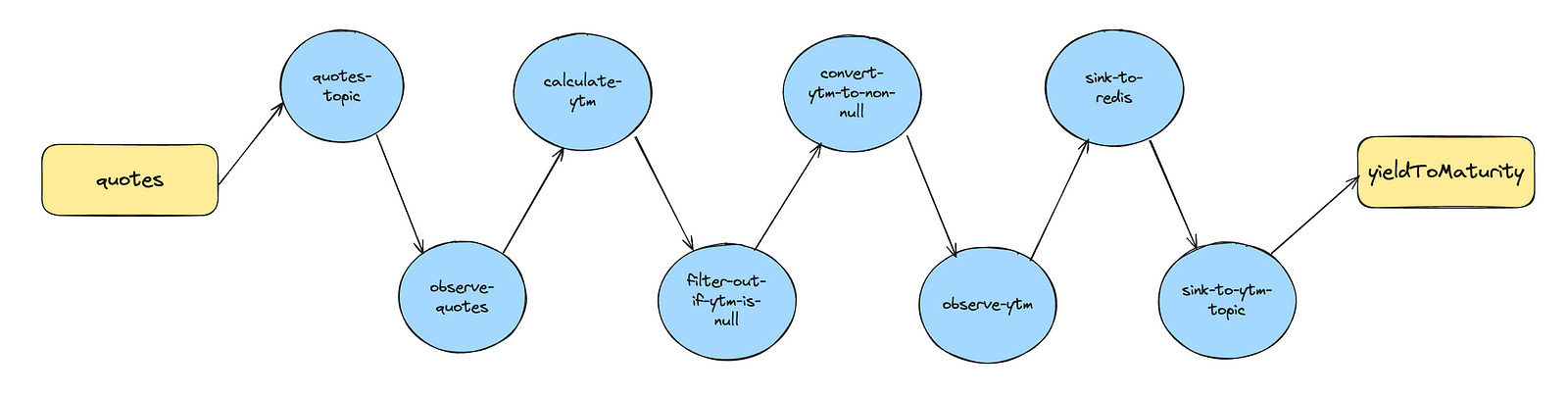
Therefore, we define our topology in the YtmTopologyBuilder class, which constructs the stream processing logic. In order to make the code more readable, we make use of Kotlin’s extension functions, so we can create our own DSL to define the topology. Here is an example of how the topology is built and configured:
class YtmTopologyBuilder(
private val config: YtmTopologyConfig,
private val ytmCalculationService: YtmCalculationService,
private val redisPort: RedisPort
) {
fun build(): Topology {
val streamsBuilder = StreamsBuilder()
streamsBuilder.streamQuotes()
.calculateYtm()
.sinkToRedis()
.sinkToKafka()
return streamsBuilder.build()
}
private fun StreamsBuilder.streamQuotes(): KStream<Isin, Quote> {
return stream(
config.inputTopic,
Consumed.`as`<Isin, Quote>("quotes-topic")
.withKeySerde(isinSerde)
.withValueSerde(quoteSerde)
)
}
private fun KStream<Isin, Quote>.calculateYtm(): KStream<Isin, YieldToMaturity> {
return mapValues(
{ isin, quote -> ytmCalculationService.calculateYtm(isin, quote) },
Named.`as`("calculate-ytm")
).filter(
{ _, ytm -> ytm != null },
Named.`as`("filter-out-if-ytm-is-null")
).mapValues(
{ _, ytm -> ytm!! },
Named.`as`("convert-ytm-to-non-null")
)
}
private fun KStream<Isin, YieldToMaturity>.sinkToRedis(): KStream<Isin, YieldToMaturity> {
return peek(
{ isin, ytm ->
redisPort.publishYieldToMaturity(isin, ytm)
},
Named.`as`("sink-to-redis")
)
}
private fun KStream<Isin, YieldToMaturity>.sinkToKafka() {
to(
config.outputTopic,
Produced
.`as`<Isin, YieldToMaturity>("sink-to-ytm-topic")
.withKeySerde(isinSerde)
.withValueSerde(ytmSerde)
)
}
}Configuring the Kafka Stream
The configuration for Kafka Streams is encapsulated in the YtmTopologyConfig data class. This class holds the necessary properties for setting up the Kafka Streams application, including the input and output topics and the Kafka Streams properties.
/**
* Configuration for our Kafka Streams topology.
* @property inputTopic The topic from which data will be consumed.
* @property outputTopic The topic to which data will be produced.
* @property kafkaStreamsProperties The Kafka Streams properties.
*/
data class YtmTopologyConfig(
val inputTopic: String,
val outputTopic: String,
val kafkaStreamsProperties: Properties
)Starting the Kafka Stream
And lastly, we need to start the Kafka Stream. But before that, we need to ensure everything is set up to run smoothly and stop gracefully. Starting the streams kicks off the processing defined in our topology.
But what happens when the service is stopped? Whether it’s a manual shutdown or an unexpected interruption, we need to clean up resources properly. That’s why we add a shutdown hook. This ensures the Kafka Streams instance closes gracefully, releasing connections and committing any necessary state, so we don’t leave Kafka or other components in a bad state.
Here’s how we set it all up:
private val logger = KotlinLogging.logger {}
fun startKafkaStreams(
config: YtmTopologyConfig,
ytmCalculationService: YtmCalculationService,
redisPort: RedisPort
): KafkaStreams {
val topology = buildTopology(config, ytmCalculationService, redisPort)
val kafkaStreams = KafkaStreams(topology, config.kafkaStreamsProperties)
kafkaStreams.start()
Runtime.getRuntime().addShutdownHook(Thread(kafkaStreams::close))
logger.info { "KafkaStreams started" }
return kafkaStreams
}
private fun buildTopology(
config: YtmTopologyConfig,
ytmCalculationService: YtmCalculationService,
redisPort: RedisPort
): Topology {
val topology = YtmTopologyBuilder(config, ytmCalculationService, redisPort).build()
val topologyDescription = topology.describe().toString()
logger.info { topologyDescription }
return topology
}Storing and Publishing YTM with Redis
Once we calculate the Yield to Maturity (YTM) for each bond quote, the next step is making it available for real-time streaming. That’s where Redis comes in. We use Redis not only to store the YTM values but also to publish them to connected clients. This setup allows us to efficiently stream updates to the frontend via WebSockets, ensuring users always have the latest data at their fingertips.
Redis Adapter Implementation
At the core of our Redis integration is the RedisAdapter class, which implements the RedisPort interface. This class takes care of all the heavy lifting when it comes to interacting with Redis. It handles storing YTM values, retrieving the latest data, and publishing updates in real time.
If you’re wondering about the naming — Adapter and Port — it’s because we’re following the Hexagonal Architecture. In this design pattern, the Port represents an abstract interface defining what the application needs or offers, while the Adapter is the implementation that connects this interface to a specific technology — in this case, Redis.
To keep things clean and consistent, the adapter also manages data serialisation and deserialisation. Whether it’s a client requesting the latest YTM or a new update being published to Redis channels, the RedisAdapter ensures everything is formatted correctly and seamlessly flows through the system.
One interesting aspect of our implementation is the concurrent map we maintain. This map tracks ISINs (bond identifiers) against locally unique listener IDs. It plays a key role in two ways:
Single Subscription Per ISIN: We ensure that only one subscription exists per ISIN within a service instance. This avoids duplicate Redis connections and optimises resource usage.
Caller Abstraction: The caller of the API doesn’t need to worry about managing listener IDs. They can simply unsubscribe from the async listener without needing to know or track the listener ID, making the API simple and user-friendly.
Here is a part of the implementation of the RedisAdapter related to publishing the YTM value:
class RedisAdapter(
private val redisClient: RedissonClient
) : RedisPort {
private val logger = KotlinLogging.logger {}
private val subscriptions = ConcurrentMap<Isin, Int>()
override fun publishYieldToMaturity(isin: Isin, ytm: YieldToMaturity) {
val redisMap = mapOf("ytm" to ytm.toPlainString())
publish(isin, redisMap)
store(isin, redisMap)
}
private fun store(isin: Isin, values: Map<String, String>) {
val rMap = redisClient.getMap<String?, String?>(isin)
try {
rMap.putAll(values)
} catch (e: Exception) {
logger.error { "Redis error storing object to bucket: $isin" }
}
}
private fun publish(isin: Isin, message: Map<String, String>) {
val encodedMap = Json.encodeToString(message)
val topic = redisClient.getTopic(isin)
try {
val numSubscribers = topic.publish(encodedMap)
logger.debug { "Message published successfully for $isin, number of subscribers: $numSubscribers" }
} catch (e: Exception) {
logger.error { "Redis error publishing message to topic: $isin" }
}
}Streaming YTM Updates via WebSockets
Once the YTM data is stored and published in Redis, the final step is delivering this data to our customers in real time. This process involves three key components: retrieving and subscribing to Redis data, bridging Redis and WebSocket connections via the YtmProvider, and the WebSocket implementation itself. Here’s how it all comes together:
Retrieving and Subscribing Data from Redis
The RedisAdapter doesn’t just store and publish data — it also handles retrieving and subscribing to YTM updates. On a microservices setup, it would make sense to have distinct implementations for the service publishing the YTM to Redis and the service that consumes the YTM and stream to the customers, but in our demo we’re doing everything together to make it simpler.
Here’s how the rest of the implementation of our RedisAdapter looks like:
override fun getYieldToMaturity(isin: Isin): YieldToMaturity? {
val redisMap = get(isin)
return if (redisMap.isNullOrEmpty()) {
null
} else {
YieldToMaturity(redisMap["ytm"]!!)
}
}
override fun subscribeYieldToMaturity(isin: Isin, callback: (YieldToMaturity) -> Unit) {
subscribe(isin) { message ->
callback(YieldToMaturity(message["ytm"]!!))
}
}
private fun get(isin: Isin): Map<String, String>? {
return redisClient.getMap<String?, String?>(isin).readAllMap()
}
private fun subscribe(isin: Isin, callback: (Map<String, String>) -> Unit) {
subscriptions.computeIfAbsent(isin) {
val topic = redisClient.getTopic(isin)
topic.addListenerAsync(String::class.java) { _, message ->
val decodedMap = Json.decodeFromString<Map<String, String>>(message)
callback(decodedMap)
}.get()
}
}Bridging Redis and WebSocket
In our implementation, the YtmProvider acts as the glue between Redis and the WebSocket connections. Its job is to manage Redis subscriptions and ensure efficient resource usage, no matter how many clients are connected.
Here’s how it works:
SharedFlow for Updates: For each ISIN, the YtmProvider creates a Kotlin SharedFlow to broadcast updates to all connected clients. This ensures clients receive real-time data without duplicating Redis subscriptions.
On-Demand Subscription Management:
- A Redis subscription is created only when the first WebSocket client connects for a given ISIN.
- When the last client disconnects, the Redis subscription is automatically closed, freeing up resources.
This design keeps things lightweight, scalable, and avoids unnecessary load on Redis.
Here’s how the implementation looks like:
class YtmProvider(
private val redisPort: RedisPort,
private val scope: CoroutineScope = CoroutineScope(Dispatchers.IO)
) {
private val logger = KotlinLogging.logger {}
private val isinFlows = ConcurrentHashMap<Isin, SharedFlow<String>>()
private val isinSubscriptions = ConcurrentHashMap<Isin, AtomicInteger>()
fun subscribe(isin: Isin): Flow<String> {
logger.debug { "New WebSocket connection for $isin" }
val flow = getFlow(isin)
val subscriptions = isinSubscriptions[isin]!!.incrementAndGet()
logger.debug { "Number of Subscriptions for $isin: $subscriptions" }
return flow
}
fun unsubscribe(isin: Isin) {
val subscriptions = isinSubscriptions[isin]?.decrementAndGet()
logger.debug { "Number of Subscriptions for $isin: $subscriptions" }
if (subscriptions == 0) {
cleanUp(isin)
}
}
fun closeAll() {
logger.info { "Closing all subscriptions" }
isinFlows.keys.forEach { cleanUp(it) }
}
private fun cleanUp(isin: Isin) {
logger.debug { "Cleaning up $isin" }
redisPort.unsubscribeYieldToMaturity(isin)
isinSubscriptions.remove(isin)
isinFlows.remove(isin)
}
private fun getFlow(isin: Isin): SharedFlow<String> {
return isinFlows.computeIfAbsent(isin) {
val flow = MutableSharedFlow<String>(replay = 1)
isinSubscriptions[isin] = AtomicInteger(0)
redisPort.getYieldToMaturity(isin)?.let {
scope.launch {
flow.emit(it.toPlainString())
}
}
redisPort.subscribeYieldToMaturity(isin) {
scope.launch {
flow.emit(it.toPlainString())
}
}
flow.asSharedFlow()
}
}
}WebSocket Implementation
The WebSocket implementation, built using Ktor, brings everything together by streaming the YTM updates to connected clients.
When a client connects, the WebSocket subscribes to updates for the requested ISIN via the
YtmProvider.The latest YTM value is immediately sent to the client, either:
-> usingRedisPort#getYieldToMaturitywhen the flow is created
-> or by replaying the last element of the shared flow, if the flow already existsSubsequent updates from Redis are streamed to the client in real time via the SharedFlow.
This ensures clients always have access to the most up-to-date YTM data with minimal latency. Here’s how the WebSocket session might look like:
fun Application.configureSockets(ytmProvider: YtmProvider) {
install(WebSockets) {
pingPeriod = 10.seconds
timeout = 15.seconds
maxFrameSize = 1024
masking = false
}
routing {
webSocket("/ytm/{isin}") {
val isin = call.parameters["isin"] ?: return@webSocket close(
CloseReason(
CloseReason.Codes.CANNOT_ACCEPT,
"Missing isin parameter"
)
)
runCatching {
launch {
ytmProvider.subscribe(isin).collect {
send(Frame.Text(it))
}
}
try {
closeReason.await()
} finally {
ytmProvider.unsubscribe(isin)
}
}.onFailure {
ytmProvider.closeAll()
}
}
}
}Conclusion
Building a real-time streaming pipeline for bond Yield to Maturity (YTM) was a challenging yet rewarding engineering journey. From calculating YTM with Kafka Streams, to managing Redis for storage and pub/sub, and finally streaming updates to customers via WebSockets, every part of the architecture was designed to be efficient, scalable, and developer-friendly.
The result? A system that delivers live YTM data to customers seamlessly, empowering them to make better investment decisions. Along the way, we learned how to leverage tools like Kotlin Coroutines, Ktor WebSockets, and Kafka Streams to build a robust and maintainable solution.
If you’re curious to dive deeper into the code and experiment with the architecture yourself, we’ve made a full demo available on GitHub. Check it out here: https://github.com/traderepublic/ytm-stream . We’d love to hear your thoughts, feedback, or questions — feel free to reach out!
Further Reading and Resources
If you’re excited to explore more about the technologies we used in this project, here are some great resources to dive deeper:
Kafka Streams
Redis Pub/Sub
Ktor WebSocket
Kotlin Flows
These resources are perfect for getting hands-on experience and expanding your knowledge about the tools and techniques behind our YTM streaming architecture. Happy learning!
 | A guest post by
|